「SAVACAN」担当のMKです。
今回のブログではAWSでのログ管理の基本となるCloudWatchについて紹介します。
CloudWatchではコンピューティング、データベース、Lambda、ストレージ、APIなどアカウント全体のログをまとめて管理できます。
ログ管理の他、CPU、メモリ(カスタムメトリクス)、ディスクI/O、ネットワークトラフィックのメトリクス管理ができ、アラートメールやAuto Scaling連携などが行えますので、うまく利用して運用の負担を減らしていきましょう!
本ブログでは
・EC2の負荷、messagesログをCloudWatchで確認
・EC2の使用状況に応じてアラートメールを通知
の2点を取り上げたいと思います。
EC2のログを監視するための前提として、Amazon AWSのアカウント取得とEC2インスタンスの作成が完了しているものとさせて頂きます。
本記事の内容としては、Amazon AWSやEC2の設定をしたことがある方、IAMがどういうものか何となく理解できている方に向けたものとなっております。
IAMロール権限の設定
初めにEC2のログをCloudWatchで監視するためには、EC2のセキュリティにIAMロールの付与が必要になります。
[IAMダッシュボード]のアクセス管理から[ロール]をクリックします。

ロールの一覧画面から[ロールを作成]をクリックします。

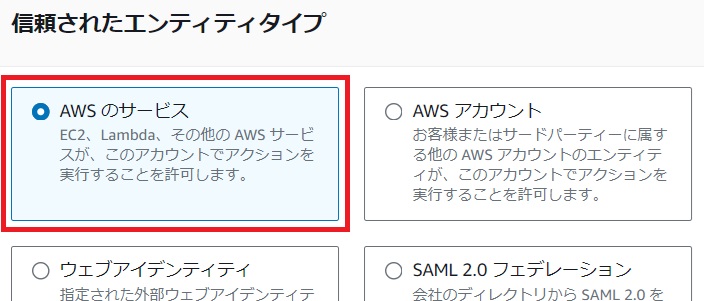
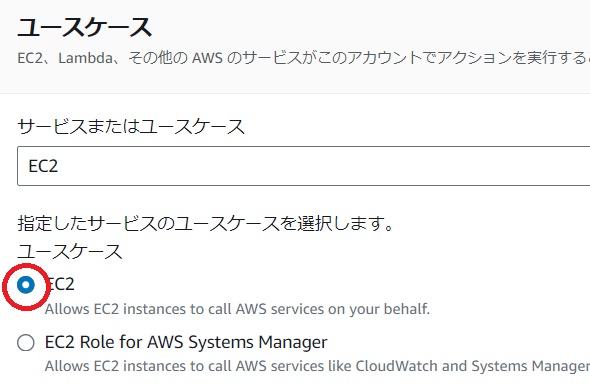
[信頼されたエンティティを選択]画面で信頼されたエンティティタイプに[AWSのサービス]、ユースケースに[EC2]を選択して[次へ]をクリックします。
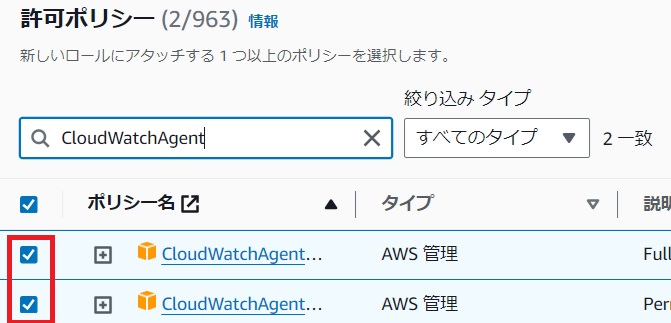
[許可ポリシー]の選択画面で以下の2個を選択して[次へ]をクリックします。
CloudWatchAgentAdminPolicy
CloudWatchAgentServerPolicy
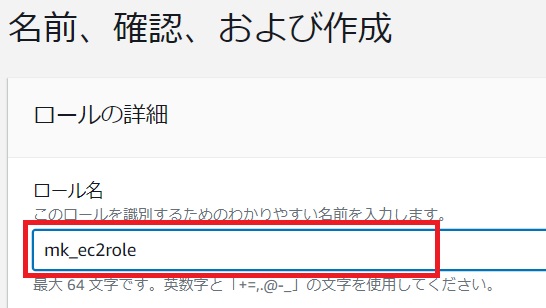
[名前、確認、および作成]画面で任意のロール名を入力し[ロールを作成]をクリックします。
作成するとロールの一覧画面に戻りますので作成したロールがあるか確認をします。
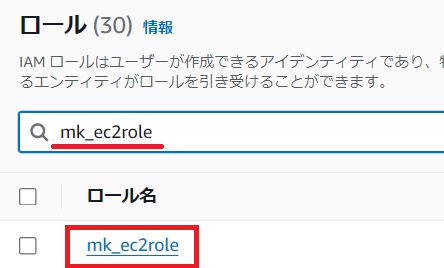
作成したロールを確認して次にEC2にIAMロールを付与します。
EC2へのIAMロール付与
[EC2ダッシュボード]の[インスタンス]をクリックします。

インスタンスを選択し[アクション]のプルダウンから[セキュリティ]→[IAMロールを変更]をクリックします。
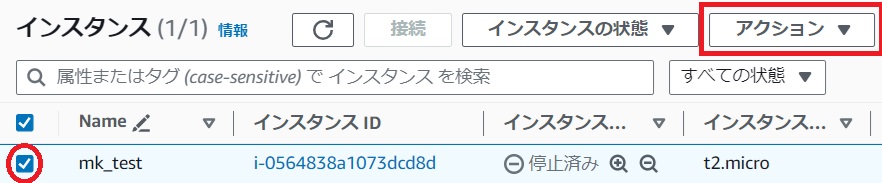
[IAMロールを変更]画面で作成したIAMロールを選択し保存します。

保存後にEC2の[セキュリティ]タブで[IAMロール]に選択したロールが表示されていれば登録成功です。
以上でIAMロールとEC2の連携は完了です。
続いてEC2のインスタンスにcloudwatch-agentをインストール、設定します。
EC2へのcloudwatch-agent設定
インスタンスのOSはAmazon Linux release 2023.5.20240701を使用しています。
まずはcloudwatch-agentのパッケージをインストールします。
yum install -y amazon-cloudwatch-agentインストール完了後にCloudWatchエージェントの設定ファイルを作成します。
[amazon-cloudwatch-agent-config-wizard]を実行して対話式で設定していきます。
お使いの環境に合わせて設定をしてください。
/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard使用するOSの種類
On which OS are you planning to use the agent?
1. linux
2. windows
3. darwin
default choice: [1]:
1EC2かオンプレミスの環境か
Trying to fetch the default region based on ec2 metadata...
I! imds retry client will retry 1 timesAre you using EC2 or On-Premises hosts?
1. EC2
2. On-Premises
default choice: [1]:
1CloudWatchAgentの実行ユーザー
Which user are you planning to run the agent?
1. cwagent
2. root
3. others
default choice: [1]:
2StatsDデーモン(CloudWatchAgentのカスタムメトリクス取得)の利用
Do you want to turn on StatsD daemon?
1. yes
2. no
default choice: [1]:
2CollectD(CloudWatchAgentでメモリ使用率、ディスク利用率などのカスタムメトリクス監視)の利用
Do you want to monitor metrics from CollectD? WARNING: CollectD must be installed or the Agent will fail to start
1. yes
2. no
default choice: [1]:
2CPU、メモリのカスタムメトリクスを収集するか
Do you want to monitor any host metrics? e.g. CPU, memory, etc.
1. yes
2. no
default choice: [1]:
11コア当たりCPUメトリクスを収集するか
Do you want to monitor cpu metrics per core?
1. yes
2. no
default choice: [1]:
1ec2ディメンションをを全てのメトリクスに追加するか
Do you want to add ec2 dimensions (ImageId, InstanceId, InstanceType, AutoScalingGroupName) into all of your metrics if the info is available?
1. yes
2. no
default choice: [1]:
1メトリクスをインスタンスIDで集約するか
Do you want to aggregate ec2 dimensions (InstanceId)?
1. yes
2. no
default choice: [1]:
1メトリクス収集間隔
Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file.
1. 1s
2. 10s
3. 30s
4. 60s
default choice: [4]:
4メトリクス収集の設定
Which default metrics config do you want?
1. Basic
2. Standard
3. Advanced
4. None
default choice: [1]:
2
Current config as follows:
{
"agent": {
"metrics_collection_interval": 60,
"run_as_user": "root"
},
"metrics": {
"aggregation_dimensions": [
[
"InstanceId"
]
],
"append_dimensions": {
"AutoScalingGroupName": "${aws:AutoScalingGroupName}",
"ImageId": "${aws:ImageId}",
"InstanceId": "${aws:InstanceId}",
"InstanceType": "${aws:InstanceType}"
},
"metrics_collected": {
"cpu": {
"measurement": [
"cpu_usage_idle",
"cpu_usage_iowait",
"cpu_usage_user",
"cpu_usage_system"
],
"metrics_collection_interval": 60,
"resources": [
"*"
],
"totalcpu": false
},
"disk": {
"measurement": [
"used_percent",
"inodes_free"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"diskio": {
"measurement": [
"io_time"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"mem": {
"measurement": [
"mem_used_percent"
],
"metrics_collection_interval": 60
},
"swap": {
"measurement": [
"swap_used_percent"
],
"metrics_collection_interval": 60
}
}
}
}設定に問題がないか
Are you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items.
1. yes
2. no
default choice: [1]:
1CloudWatch Log Agentが既に存在しているか
Do you have any existing CloudWatch Log Agent (http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/AgentReference.html) configuration file to import for migration?
1. yes
2. no
default choice: [2]:
2CloudWatchで監視したいログファイルがあるか
Do you want to monitor any log files?
1. yes
2. no
default choice: [1]:
1ログファイルのパス
Log file path:
/var/log/messages
Log group name:
default choice: [messages]
messagesロググループのクラス(INFREQUENT_ACCESSはデータ転送量が安いが機能制限有り)
Log group class:
1. STANDARD
2. INFREQUENT_ACCESS
default choice: [1]:
1ログストリームの名前(CloudWatch側で表示されます)
Log stream name:
default choice: [{instance_id}]
mk_messagesログ保持期間
Log Group Retention in days
1. -1
2. 1
3. 3
4. 5
5. 7
6. 14
7. 30
8. 60
9. 90
10. 120
11. 150
12. 180
13. 365
14. 400
15. 545
16. 731
17. 1096
18. 1827
19. 2192
20. 2557
21. 2922
22. 3288
23. 3653
default choice: [1]:
3追加で収集したいログがあるか
Do you want to specify any additional log files to monitor?
1. yes
2. no
default choice: [1]:
2AWS x-rayを利用するか
Do you want the CloudWatch agent to also retrieve X-ray traces?
1. yes
2. no
default choice: [1]:
2
Existing config JSON identified and copied to: /opt/aws/amazon-cloudwatch-agent/etc/backup-configs
Saved config file to /opt/aws/amazon-cloudwatch-agent/bin/config.json successfully.
Current config as follows:
{
"agent": {
"metrics_collection_interval": 60,
"run_as_user": "root"
},
"logs": {
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/var/log/messages",
"log_group_class": "STANDARD",
"log_group_name": "mk_messages",
"log_stream_name": "messages",
"retention_in_days": 3
}
]
}
}
},
"metrics": {
"aggregation_dimensions": [
[
"InstanceId"
]
],
"append_dimensions": {
"AutoScalingGroupName": "${aws:AutoScalingGroupName}",
"ImageId": "${aws:ImageId}",
"InstanceId": "${aws:InstanceId}",
"InstanceType": "${aws:InstanceType}"
},
"metrics_collected": {
"cpu": {
"measurement": [
"cpu_usage_idle",
"cpu_usage_iowait",
"cpu_usage_user",
"cpu_usage_system"
],
"metrics_collection_interval": 60,
"resources": [
"*"
],
"totalcpu": false
},
"disk": {
"measurement": [
"used_percent",
"inodes_free"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"diskio": {
"measurement": [
"io_time"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"mem": {
"measurement": [
"mem_used_percent"
],
"metrics_collection_interval": 60
},
"swap": {
"measurement": [
"swap_used_percent"
],
"metrics_collection_interval": 60
}
}
}
}
Please check the above content of the config.
The config file is also located at /opt/aws/amazon-cloudwatch-agent/bin/config.json.
Edit it manually if needed.設定ファイルをSSMパラメータストアにアップロードするか
Do you want to store the config in the SSM parameter store?
1. yes
2. no
default choice: [1]:
2
Program exits now.
[root@ip-***-**-**-*** ~]#以上で設定は完了となります。
設定が完了すると以下の設定ファイルが作成されます。
/opt/aws/amazon-cloudwatch-agent/bin/config.jsoncloudwatch-agent起動
設定ファイルを作成したらEC2のインスタンスでcloudwatch-agentを起動します。
/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json -s自動起動の設定をします。
ln -s /opt/aws/amazon-cloudwatch-agent/bin/config.json /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.jsonsystemctl enable amazon-cloudwatch-agentcloudwatch-agentが起動すると、負荷・ログなどのデータをCloudWatchへ送信開始します。
CloudWatchでmessagesログの確認
ここまでの設定でCloudWatchにEC2のログが転送されていますので確認してみます。
CloudWatchの[ログ]から[ロググループ]をクリックします。

ロググループに先ほど設定をしたmk_messagesのロググループが作成されているか確認します。
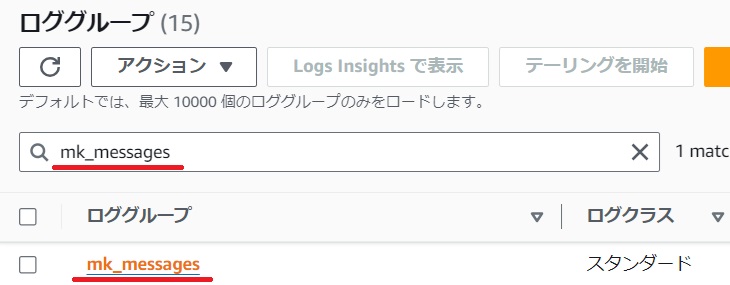
mk_messagesをクリックしログストリームからmessagesをクリックします。
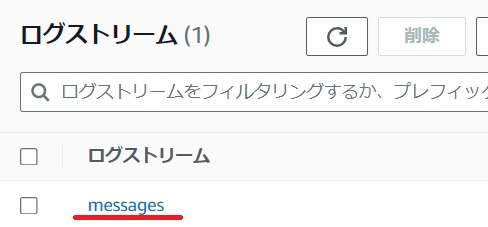
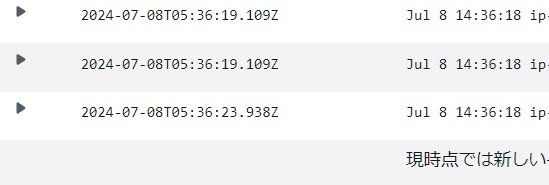
/var/log/messagesが転送されていることが確認できました。
EC2インスタンスのログがCloudWatchに転送できていますね!
CloudWatchでメトリクスの確認
ここまでの設定でいったんCloudWatchで受信するEC2のメトリクスを確認してみます。
ここではネットワーク負荷をグラフ化してみます。
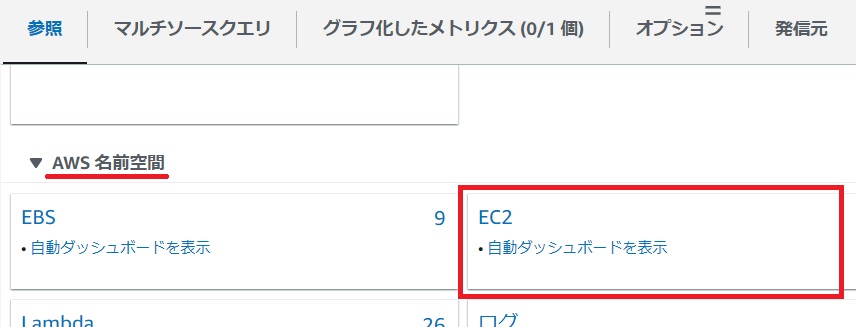
CloudWatchの[メトリクス]から[すべてのメトリクス]を選択します。

[AWS名前空間]から[EC2]をクリックします。
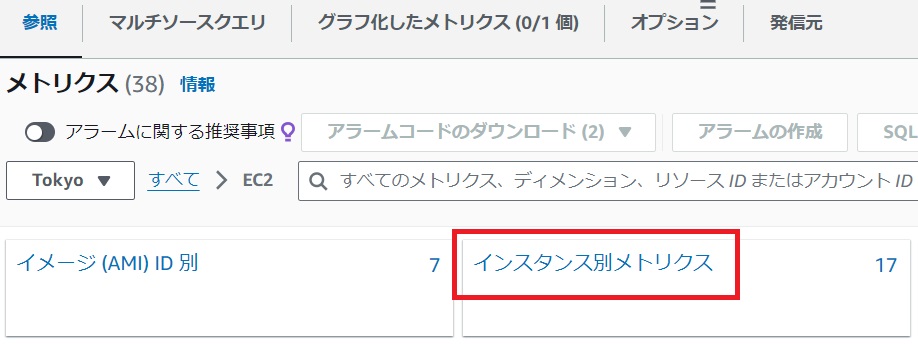
メトリクスから[インスタンス別メトリクス]をクリックします。
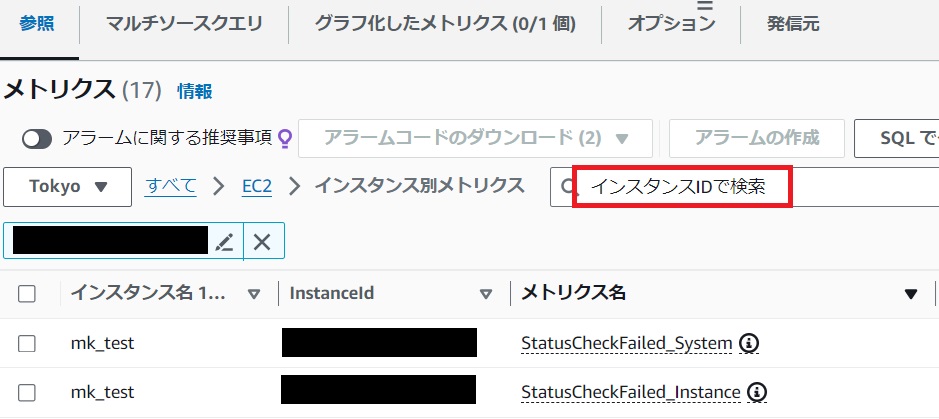
[インスタンス別メトリクス]画面でEC2とCloudWatchを連携したインスタンスIDで検索するとメトリクスが取得できていることが確認できます。
今回はNetworkIn(ネットワーク受信量) をグラフ化してみます。
[NetworkIn]をクリックして[このメトリクスのみをグラフに表示]をクリックします。
[グラフ化したメトリクス]タブでNetworkInのグラフが表示されることを確認します。
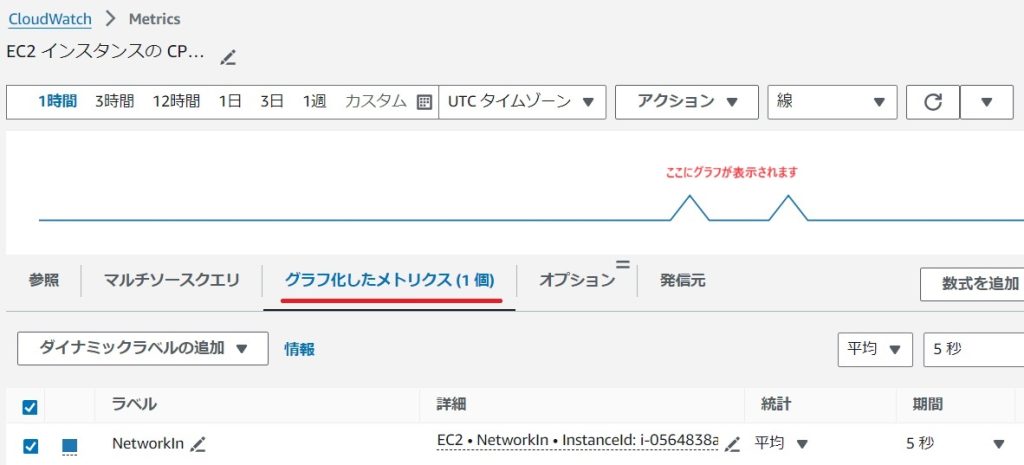
グラフが少し増加している時間に100MB程度のデータをダウンロードしています。
メトリクスから負荷グラフが作成できましたね!
EC2の使用状況に応じてアラートメールを通知
最後にCloudwatchの監視の自動化を試してみます。
全てのEC2インスタンスのログとグラフをCloudWatchで管理しても目視での見落としや、休日・夜間などリアルタイムに監視できないタイミングが出てくる場合があります。
運用では、CPU負荷が〇%を超えたとき、ログに○○〇という文字列があったときなどに自動で通知する仕組みを構築する事で、ローコストで見落としの削減や24/365のリアルタイム監視を実現できます。
今回はEC2のインスタンスの/var/log/messagesにサーバー再起動を示す以下の文字列があったときにメールで通知する仕組みを設定します。
Finished systemd-reboot.service - System Reboot.AWSのサービス構成は次のようになります。
EC2のログをCloudWatchに転送し、ログから指定の文字列を検知したらアラートとしてAmazon SNS経由でユーザーにメール通知します。
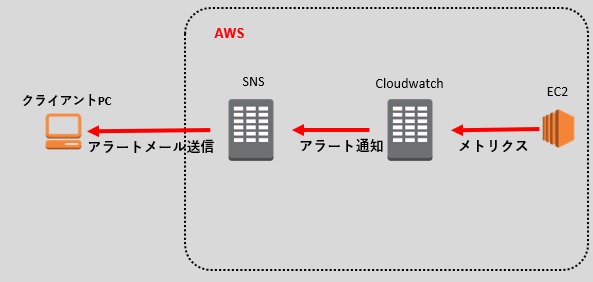
※Amazon SNSとは
Amazon Simple Notification Serviceの略称でサーバーレスで通知機能が実装できます。
フルマネージド型のサービスのためスケーラビリティの考慮をする必要がありません。
CloudWatchなどSNS以外のサービスのイベントから通知できますので便利です。
CloudWatchでログの異常検知作成
EC2のログから検知したい文字列を設定します。
作成した[mk_messages]のロググループから[メトリクスフィルター]タブを選択し[メトリクスフィルターを作成]をクリックします。
[パターンを定義]画面で[フィルタパターン]に
"Finished systemd-reboot.service - System Reboot."と入力します。検知したい文字列をダブルコーテーションで囲む必要がありますので注意してください。
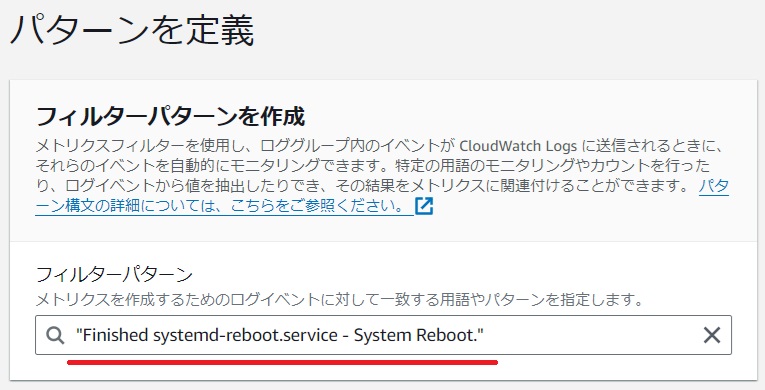
[パターンをテスト]でイベントメッセージをログ記録の入力枠自動でメッセージのテンプレートが入力されますので、[Finished systemd-reboot.service – System Reboot.]の文字列を挿入します。
準備ができたら[パターンをテスト]をクリックします。
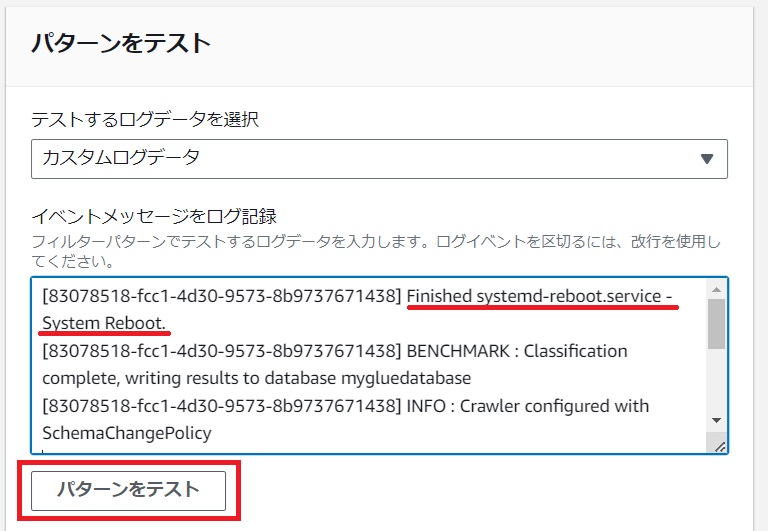
テスト結果で検知したい文字列が一致した行が見つかったことを確認し[NEXT]をクリックします。
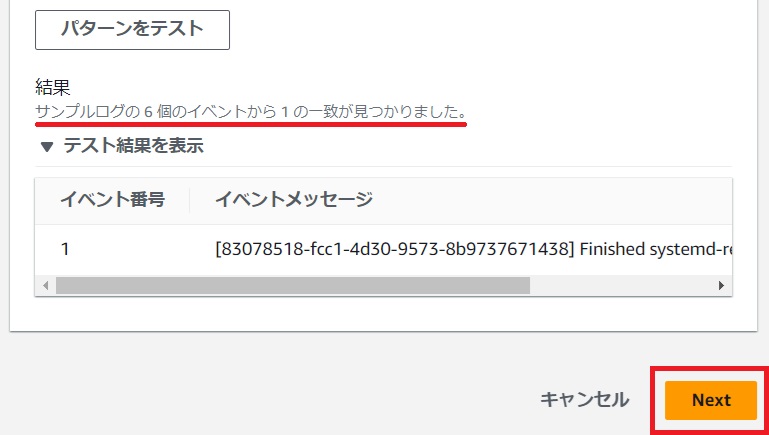
[メトリクスの割り当て]画面で任意でフィルター名、メトリクス名前空間、メトリクス名、メトリクス値を登録して[NEXT]をクリックします。
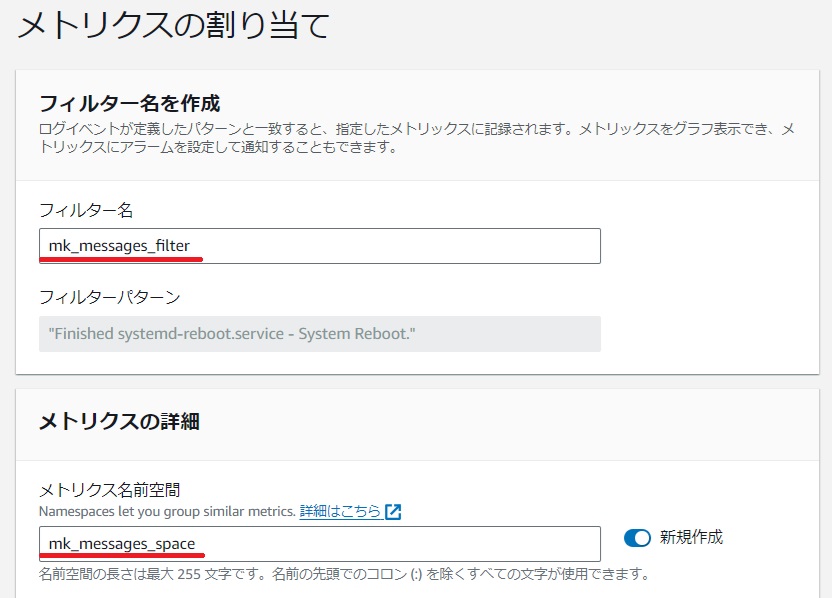
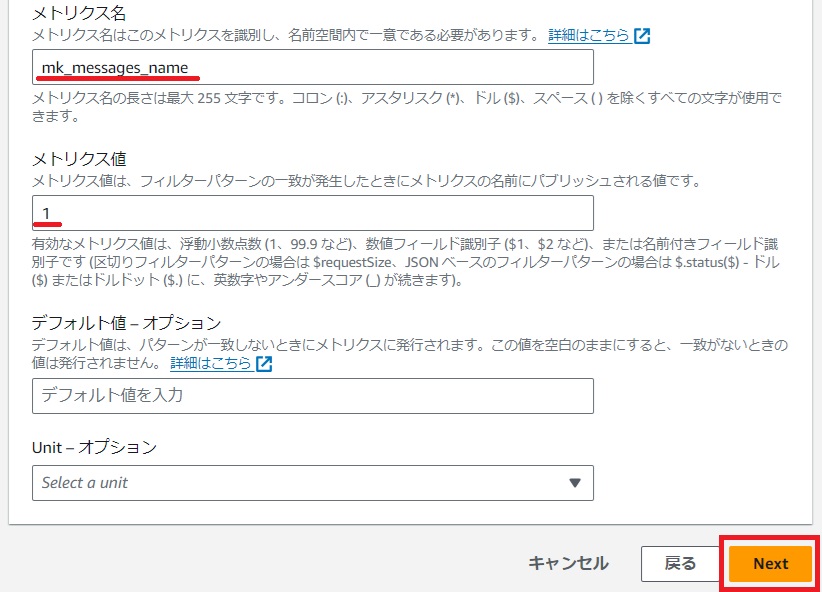
確認画面で[メトリクスフィルターを作成]をクリックします。
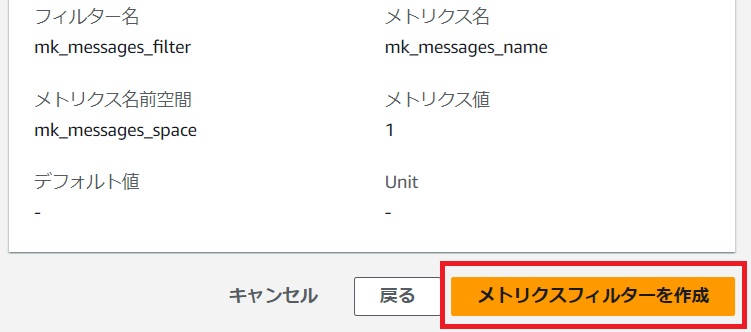
作成すると[メトリクスフィルター]タブに戻ります。
メトリクスフィルターが作成されていますのでチェックを付けて[アラームを作成]をクリックします。
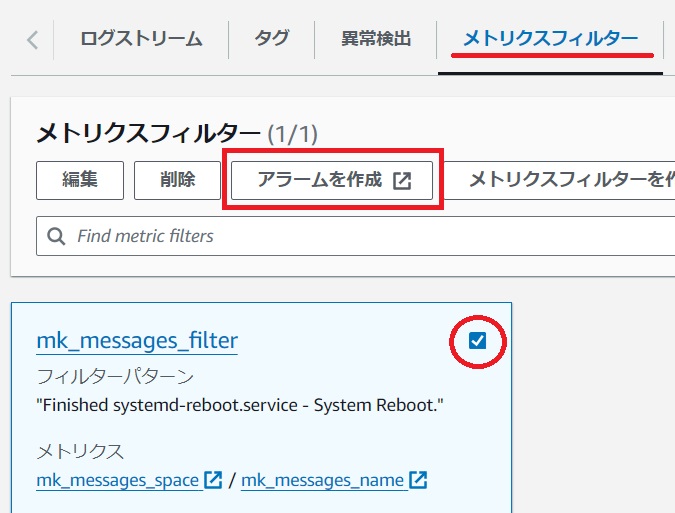
[メトリクスと条件の指定]画面で統計と期間を運用に合わせて変更します。
メトリクス名はアラーム作成時にデフォルトで入力されますのでそのままとします。
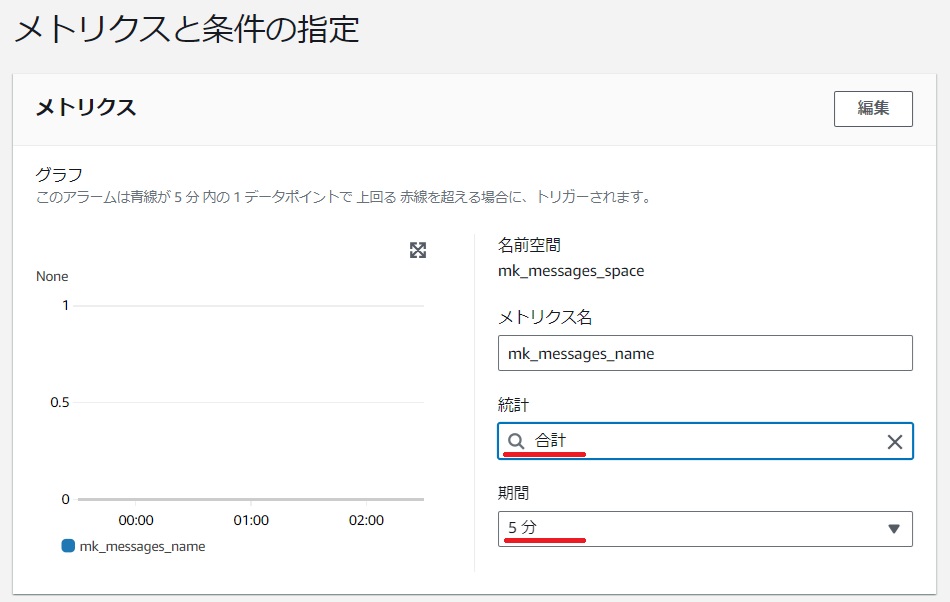
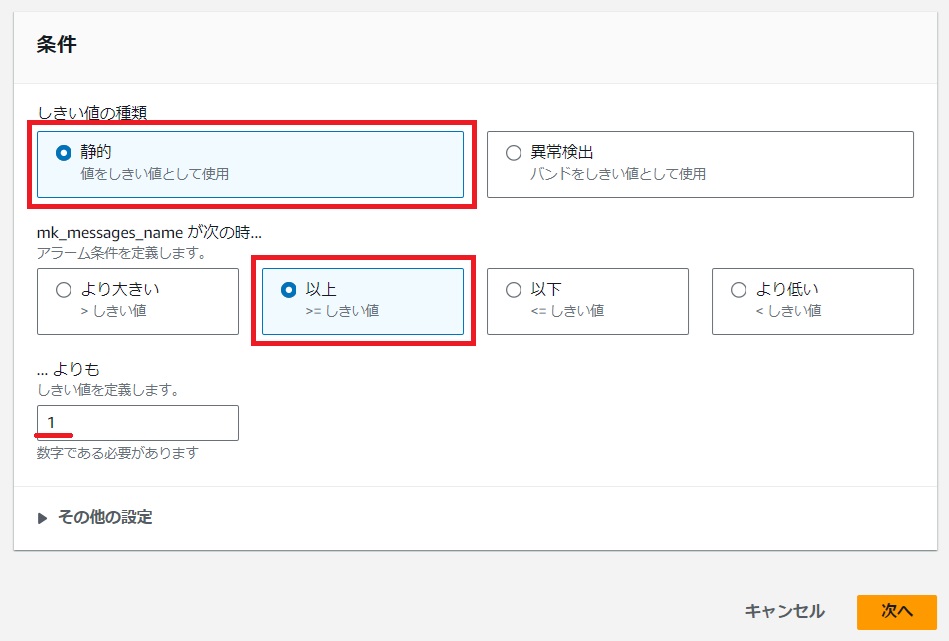
条件で今回は1回以上の検知とします。
[次へ]をクリックします。
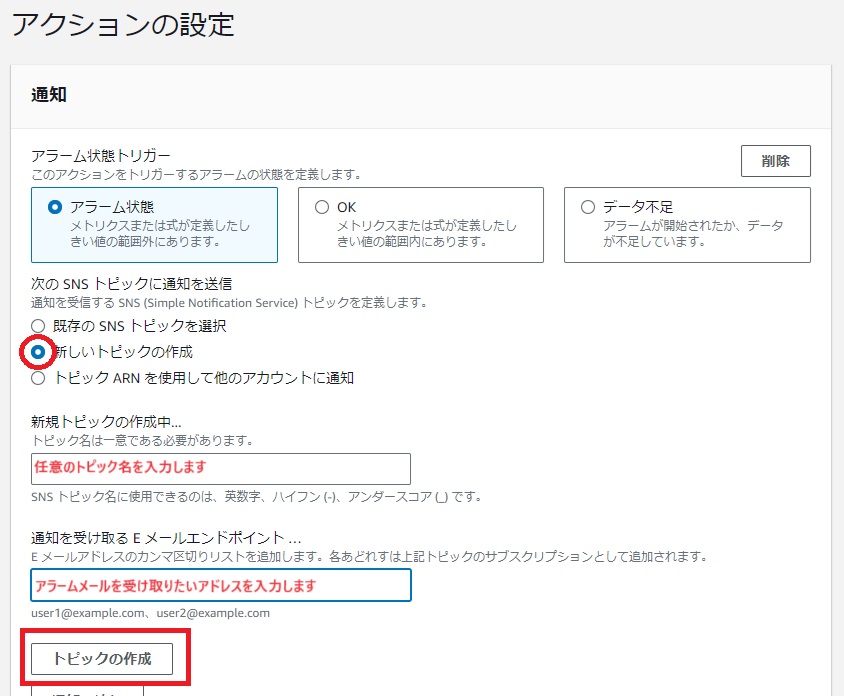
通知させたいメールアドレス情報をAmazon SNSに登録します。
トピック名とEメールアドレスを入力して[トピックの作成]をクリックします。
Lambda、Auto Scalingなどアラート時の動作の設定項目もありますが今回はメール通知だけ設定しますので[次へ]をクリックします。
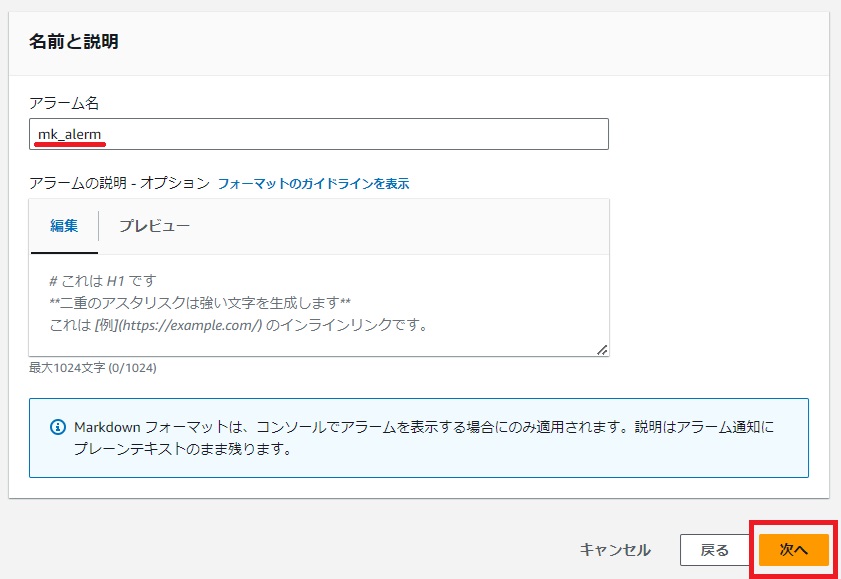
任意のアラーム名を入力し[次へ]をクリックします。
設定の確認画面で問題なければ[アラームの作成]をクリックします。
アラームの作成をするとトピックの作成で登録したメールアドレスに承認URLの記載されたメールが届きますのでクリックして承認します。
動作確認
今回はサーバー再起動時のログメッセージ
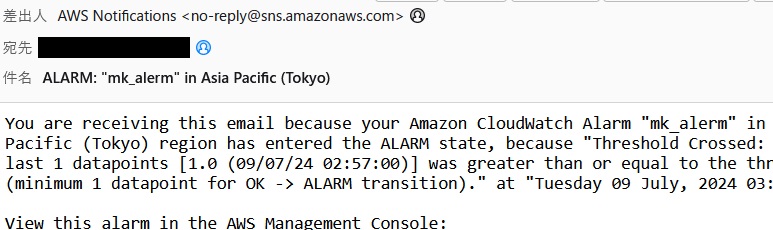
Finished systemd-reboot.service - System Reboot.を検出してアラートメールを通知しますので、動作確認としてEC2のインスタンスを再起動します。
再起動した際にトピックで指定したメールアドレスに次のメールが届けば成功です!
今回は特定メッセージの検出時にアラートメールを通知する方法をご紹介しましたが、
インスタンス負荷とAuto Scalingを組み合わせればサーバー負荷に応じてEC2のインスタンス台数を増減することや、Lambdaの実行もできます。
最後に弊社の主な保守監視体制のご紹介になりますが、
・自社開発のシステムログ解析およびアラート送信
・Zabbixによるメトリクス監視、ドメイン及びSSL期限監視
・ハードウェア障害監視
・自社監視システムによるネットワークとサービスポートの死活監視、システムの外形監視
・24時間365日の障害対応
を実施しております。
数百台のサーバーを少人数で効率よく管理するために様々な仕組みを取り入れています。
マンパワーによる監視はミスの原因ともなりますので、自動化して充実のインフラライフを!


